关键参数反演 | 土壤盐渍化程度
盐渍化是指盐分在土壤中积聚,导致土壤基本特性恶化和质量下降的过程。可由自然因素引起,也可能是人类不当生产活动引起的,是威胁生态系统的主要土壤退化过程。土壤盐渍化不仅导致植被覆盖减少,生物多样性下降,还削弱了土壤保水能力和肥力,加剧水土流失。黄河入海口孕育着风景如画的黄河三角洲,但美景背后却是严重的土壤盐渍化问题。东营市有盐碱地341万亩,占山东省盐碱地面积的38%。通过遥感监测和实地调查,获取土壤盐渍化的现状,评估陆海复杂区生态环境健康状况,以支撑区域生态系统的健康与可持续发展。土壤含盐量与EC之间存在密切的正相关关系。EC值反映了土壤中可溶性盐的浓度,这些盐分包括氯化钠和其他无机盐类。
野外调查
通过网格法布设采样点,在遥感影像中以3km×3km网格覆盖研究区(避开水面与建设用地),每个网格中心布设一个采样点,调查时根据可达性及现场情况进行微调,利用地图软件读取样点坐标,并记录土地利用现状,并利用EC110电导率仪测定表层(0cm~20cm)EC。基于GEE平台选取同期的哨兵1号雷达影像数据、哨兵2号光学影像数据计算遥感指数并结合土壤母质数据、地形坡度等环境要素数据反演得到东营辐射区的土壤EC分布。

图 陆海复杂区土壤盐渍化程度预测模型
多源数据收集与处理
研究表明学者在选取光谱指数时,常用的是植被指数和盐分指数。由于植被指数难以准确反映稀疏植被地区的光谱信息,因而目前多基于植被指数与盐分指数组合反演土壤盐渍化。依据前人经验初步选取6种盐分指数、4种盐渍化指数、13种植被指数、8种雷达指数以及9类环境协变量构建模型训练集,经过皮尔逊相关指数计算剔除高度相关的变量后利用Boruta特征选择方法选择最终进入模型训练的变量。
在训练模型时通常需要先对数据去冗余,提取关键变量降低模型的复杂度并提高运算速度,使其更易于解释,同时也有助于提高模型的性能,降低过拟合问题的出现。Boruta是一种全特征选择方法,旨在确定所有对响应变量有影响的特征。它通过对数据集进行随机森林训练,并将特征的原始重要性与通过随机打乱特征顺序得到的“影子”特征的重要性进行比较,来判断哪些特征是重要的。
具体步骤如下:
(1)特征重要性计算。给定一个数据集D={(x1,y1),(x2,y2),…,(xn,yn)},其中xi是第i个样本的特征向量,yi是其对应的标签,特征重要性计算公式如下:
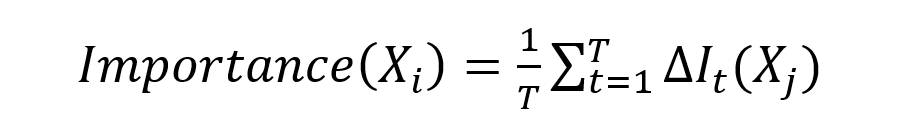
其中,T是随机森林中决策树的数量,∆It>(Xj)是第t棵决策树中特征Xj对分类性能提升的贡献,以基尼系数或熵来衡量。
(2)影子特征生成。影子特征是通过对原始特征Xj>进行随机重排生成的。对于每个原始特征Xj,其对应的影子特征记作Xjshadow,影子特征集合记作S={X1shadow,X2shadow,…,Xpshadow}。
(3)重要性比较。在每次迭代中,Boruta算法会比较原始特征和影子特征的重要性。对于每个原始特征Xj,如果其重要性Importance(Xj)显著高于所有影子特征的最高性max(Importance(S)),则认为Xj是重要特征;否则,则认为该特征是无关的。
(4)统计检验。Boruta算法采用统计检验来判断“显著高于”或“显著低于”的标准。通常会采用一定的置信水平𝛼进行假设检验,以控制特征重要性差异的统计显著性。
(5)迭代和停止条件。Boruta通过多次迭代执行上述步骤,每次迭代中剔除无关特征,并保留重要特征,直到所有特征被归类为“重要”或“无关”,或达到预设的最大迭代次数max_iter。
最终,为获取土壤盐渍化程度共选取了23个变量。利用选取的变量训练随机森林模型。随机森林的核心思想是对训练集进行自助采样,组成多个训练集,每个训练集生成一棵决策树,所有决策树组成随机森林,从而对样本进行训练并预测的机器学习算法。该方法将多个决策树组合起来以创建随机森林。随机森林只有在半数以上的基分类器出现差错时才会做出错误的预测,因而随机森林非常稳定,即使数据集中出现了一个新的数据点,整个算法也不会受到过多影响,它只会影响到一颗决策树,很难对所有决策树产生影响。

图 土壤盐渍化程度预测自变量重要性图
可解释性机器学习模型
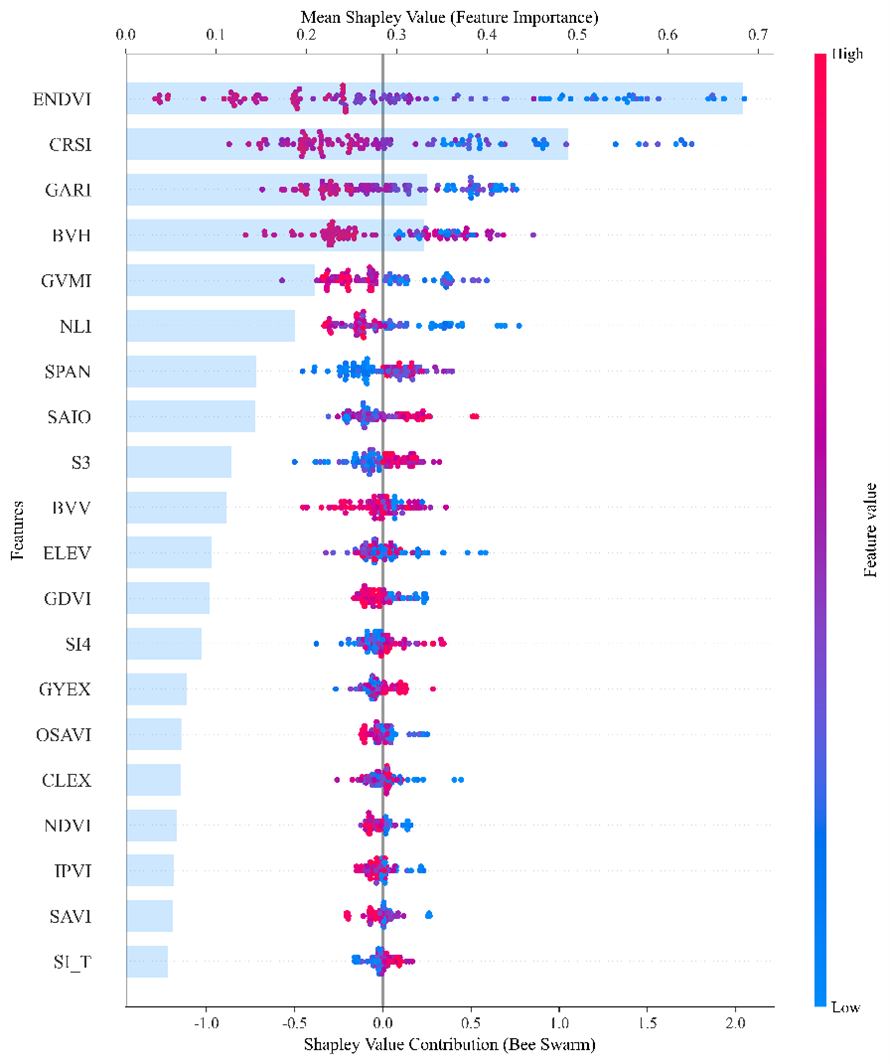
为更好地解释EC与各变量之间的关系,利用SHAP值来可视化各变量对EC的解释程度。SHAP是一种用于解释机器学习模型预测结果的重要方法,其基于Shapley值的理论背景,能够为模型的每一个输入特征分配一个贡献值,以解释该特征对模型预测结果的影响。SHAP方法将博弈论中的Shapley值思想应用到机器学习模型中,使得模型预测可以被解释为各特征贡献的加总。图 4 5表明ENDVI(Enhanced normalized differential vegetation index,增强型植被指数)、CRSI(Canopy response salinity index,冠层响应盐度指数)在预测模型中具有较高的特征贡献度,直接影响模型的输出结果。
在训练模型时通常需要先对数据去冗余,提取关键变量降低模型的复杂度并提高运算速度,使其更易于解释,同时也有助于提高模型的性能,降低过拟合问题的出现。Boruta是一种全特征选择方法,旨在确定所有对响应变量有影响的特征。它通过对数据集进行随机森林训练,并将特征的原始重要性与通过随机打乱特征顺序得到的“影子”特征的重要性进行比较,来判断哪些特征是重要的。
依据训练好的模型反演得到东营辐射区的土壤EC分布状况。下显示东营市土壤EC呈现从内陆向沿海逐渐增大的空间变化趋势,海岸带附近基本均为盐土,土壤盐渍化程度较为严重。
图 2020~2024年东营市土壤盐渍化程度分布图